2021阿里天池大赛 - 大规模内存故障预测¶
大赛概况¶
在当今大规模数据中心中,内存类故障问题频发(尤其是内存故障引发的非预期宕机问题),会导致服务器甚至整个IT基础设施稳定性、可靠性的下降,最终对业务SLA带来负面影响。近十年,工业界和学术界开展了一些关于内存故障预测相关的工作,但对工业级大规模生产环境下的内存故障预测的研究却很少。大规模生产环境业务错综复杂、数据噪声大以及不确定因素多,因此,能否提前准确预测内存故障已经成为大规模数据中心和云计算时代工业界需要研究和解决的重要问题之一。本次大赛聚焦解决大规模生产系统中的内存故障预测问题,需解决数据噪声、正负样本不均衡、稀疏矩阵处理等技术问题,同时也要保障预测算法长期稳定有效。
问题描述¶
给定一段时间的内存系统日志,内存故障地址数据以及故障标签数据,参赛者应提出自己的解决方案,以预测每台服务器是否会发生DRAM故障。具体来说,参赛者需要从组委会提供的数据中挖掘出和DRAM故障相关的特征,并采用合适的机器学习算法予以训练,最终得到可以预测DRAM故障的最优模型。数据处理方法和算法不限,但选手应该综合考虑算法的效果和复杂度,以构建相对高效的解决方案
数据描述¶
训练集包含如下两张表信息, 具体信息如下:
1)表1: memory_sample_mce_log_*.csv为mcelog上报的DRAM故障日志(mcelog是Linux基于Intel的机器检查架构(MCA)记录DRAM故障的标准工具),共6列。每列的含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 服务器代号 |
| manufacturer | integer | server manufacturer id |
| vendor | integer | memory vendor id |
| mca_id | string | mca bank代号 |
| transaction | integer | mcelog transaction |
| collect_time | string | 日志上报时间 |
2)表2: memory_sample_address_log_*.csv为从mcelog上报的DRAM故障日志中,解析出的发生DRAM故障的详细物理位置。共9列。
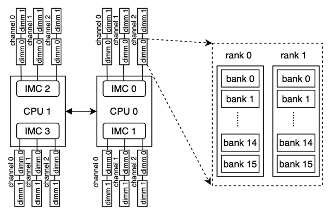
为了帮助参赛者更好地理解文件中各列的含义,我们首先说明服务器中DRAM的架构。
图1显示了服务器中DRAM的架构,其中安装到服务器的DRAM单元称为双列直插式内存模块(DIMM)。在本问题下,一台服务器最多可以安装24个DIMM,其中每个DIMM都属于一个通道,该通道连接到服务器的四个集成内存控制器(IMC)的其中一个。我们将服务器中的24个DIMM编码为0到23(以名称memory表示)。
此外,在每个DIMM内,其物理位置进一步按rank和bank组织,其中每个DIMM具有两个rank,每个rank具有16个bank。每次内存访问将仅访问32个bank之一。对于每个bank,我们可以将其视为一个二维数组,其中数组中的每个元素将存储一个位数据。在本问题下,bank有2{17}217行和2210列。因此,要确定DIMM中哪个位有错误,我们使用元组
表2详细列出了memory_sample_address_log_*.csv的每一列的具体信息,每列的含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 服务器代号 |
| manufacturer | integer | server manufacturer id |
| vendor | integer | memory vendor id |
| memory | integer | 取值范围[0,23], DIMM的代号 |
| rank | integer | 取值范围[0,1], DIMM的其中一面 |
| bank | integer | 取值范围[0,15] |
| row | integer | 取值范围[0,2**17-1] |
| col | integer | 取值范围[0,2**10-1] |
| collect_time | string | 日志上报时间 |
3)表3: memory_sample_kernel_log_*.csv是从Linux内核日志中收集的与DRAM故障相关的信息,共28列。其中,24列是布尔值。每个布尔列代表一个故障文本模板,其中True表示该故障文本模板出现在内核日志中。请注意,这里提供的模板并不保证都和DRAM故障相关,参赛者应自行判断选用哪些模板信息。下表仅列出除模版外的四列信息,每列的含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 服务器代号 |
| manufacturer | integer | server manufacturer id |
| vendor | integer | memory vendor id |
| collect_time | string | 日志上报时间 |
4)表4: memory_sample_failure_tag_*.csv为故障标签表,共5列。每列含义如下:
| 列名 | 字段类型 | 描述 |
|---|---|---|
| serial_number | string | 服务器代号 |
| manufacturer | integer | server manufacturer id |
| vendor | integer | memory vendor id |
| failure_time | string | 内存的故障时间,与上述3表里的collect_time不同 |
| tag | integer | 内存的故障类型代号 |
初赛训练集数据范围20190101 至 20190531。初赛A/B榜的测试集为memory_sample_mce_log_a/b.csv, memory_sample_address_log_a/b.csv, memory_sample_kernel_log_a/b.csv, A榜数据范围为20190601~20190630整月的日志数据,B榜数据范围为20190701~20190731整月的日志数据,选手根据测试集数据按时间维度,预测服务器是否会在未来7天内发生内存故障。初赛测试集不提供故障label。
复赛阶段,测试集的数据格式和初赛阶段相同,测试集数据范围为20190801~20190810,但是测试集数据不会提供给参赛选手。选手需要在docker代码中从指定的数据集目录中读取测试集内容,进行特征工程和模型预测,最后输出的格式也有变化,输出预测未来7天会发生内存故障的机器集合,且附带预测时间间隔(docker代码中需包含本地训练好的模型,预测时间间隔具体含义见评价指标(复赛))。在复赛中,选手可在指定的路径中读取一段历史数据,且选手需自行存储流式分钟级数据作为以后的历史数据。历史数据的时间为2019-07-01至2019-07-31,形式与格式均与初赛开放数据一致。
提交格式¶
初赛阶段,将模型在测试集上的预测文件保存为csv格式,并打包成zip压缩文件进行提交。形式如下:
1 2 3 | |
复赛阶段, 系统会流式调用选手的预测接口,每次调用会传递1min的所有数据(即将该1min内的所有出现过日志信息的服务器的数据汇总在一起传递给选手的预测接口),故而选手接收到的数据格为一个字典map,包含三个日志源,其中:map['address_log']是地址日志数据,map['kernel_log']是kernel日志数据,map['mce_log']是mcelog日志数据。每个日志源都是一个list of list,例如:map['mce_log']包含了所有机器在这一分钟内发生过的所有mcelog日志,例如,我们通过pd.DataFrame(map['mce_log'])处理后可以得到如下格式的mcelog数据,各列的含义和初赛相同:
1 2 3 4 5 6 | |
选手的预测接口要求返还形式如下:数据格式要求为json,两个key分别设置为:serial_number和pti(请勿变动)。
1 2 3 4 5 6 | |
系统在接受到用户返回结果后,会将发送时间插入后,形成最终结果予以评分,例如系统传递了一份2019-08-01 10:12:00的数据,在接受用户返回结果"{"serial_number":server_1, "pti":14}"后,会组装为"{"serial_number":server_1, "predicting time":"2019-08-01 10:12:00", "pti":14}",表示该模型在时间2019-08-01 10:12:00预测server_1将在接下来的14分钟内(即在2019-08-01:10:26:00之前)发生DRAM故障。
注:
1)预测为正常机器的结果无需写到上传文件中。单个服务器可能存在多个预测结果,但在评估过程中只考虑每个机器最早一次预测为故障的时间。例如, server_1分别在2019-08-15 00:00:00和2019-08-15 00:05:00两次被预测出未来7天内可能会发生故障,但在模型评估时只会选用2019-08-15 00:00:00的预测结果。
2)在初赛中,预测结果保存为csv文件格式,保存的csv文件无header,无index; 第一列为serial_number,第二列为预测时间(并非预测故障何时会发生的时间),格式为YYYY-MM-dd HH:mm:ss,字符串类型
3)在复赛中,参赛选手需要提交docker镜像,具体的提交方式及规范请参见镜像提交说明。
4)在复赛中,时间间隔pti以分钟为单位。
5)在复赛中,每次调用会汇总一分钟的数据,每一分钟内可能会有三种日志源同时存在的情况,也可能会缺失一种或多种,甚至没有数据(此分钟内未发生任何日志,遇到这种情况,选手需返回一个空list)的情况
7)在复赛中,选手可在指定的路径中读取一段历史数据,且选手需自行存储流式分钟级数据作为以后的历史数据。
8)复赛的选手代码可以参考后续公开在论坛中的代码示例。
评价指标(初赛)¶
本次竞赛采用F1-Score作为评价指标, 根据具体场景化的预测内容,定义相关术语和详细指标如下:
- Precision
\(n_{pp}\): 评估窗口内被预测出未来7天会发生内存故障的服务器数量
\(n_{tpp}\): 评估窗口内第一次预测故障的时间后7天内确实发生故障的服务器数量
- Recall
\(n_{pr}\): 评估窗口内所有的发生内存故障的服务器数量
\(n_{tpr}\): 评估窗口内发生内存故障的服务器被提前7天内发现的数量
- F1-Score
注:
- 初赛A榜评估窗口范围为20190601-20190630,初赛B榜评估窗口范围为20190701-20190731
- 关于同一个sn出现连续预测情况的说明:若某sn在8月10号发生故障,选手从8月2号到8月9号每天都给出该sn会故障的预测结果,则系统会选取每个周期的第一次预测(8月2号和8月9号,一个周期为7天)进行评估,则该例中,8月2号的预测为误报,3号到8号的预测被忽略,9号的预测为正确,准确率为1/(1+1)=0.5。该解释同样适应于复赛的评价。
评价指标(复赛)¶
-
predicted time interval(pti): 预测服务器在该时间间隔内发生故障,此术语仅在复赛中使用。
-
actual time interval(ati): 实际发生故障的时间减去最早一次预测为故障的时间间隔,此术语仅在复赛中使用。
-
Precision
\(n_{pp}\): 评估窗口内被预测出未来7天会发生内存故障的服务器数量
\(n_{tpp}\): 复赛中要求选手进一步为每个预测提供准确的时间间隔。我们首先用集合F表示预测准确的服务器(即,第一次预测为故障的时间与实际故障时间均落在评估窗口内,实际间隔时间大于等于0,且满足预测时间间隔小于等于实际时间间隔的服务器。预测时间间隔小于等于7天。)
- Recall
\(n_{pr}\): 评估窗口内所有的发生内存故障的服务器数量
- F1-Score
注:复赛评估窗口范围为20190801-20190831。
Last updated on 2021-08-10 by MarkoXu